今天给大家推荐的是一篇和大模型安全相关的有趣研究,名为A Comprehensive Study of Jailbreak Attack versus Defense for Large Language Models,发表于ACL 2024。文章汇集了来自新南威尔士大学、代尔夫特理工大学和南洋理工大学等多个研究团队的研究成果,深入探讨了大模型越狱攻击与防御技术的精彩博弈。让我们一起来看看,在这场激烈的攻防对决中,究竟是攻击者技高一筹,还是防御者能够化解所有危机?

研究背景
随着大语言模型(LLM)在数字时代的内容创作中占据越来越核心的地位,尽管研究人员采用了如基于人类反馈的强化学习(RLHF)等安全训练技术,以确保模型的输出能够与社会价值观相契合,进而避免生成恶意内容。然而,通过巧妙设计的提示词仍可以引导模型产出不当内容的现象,即所谓的“越狱”行为,这仍是个棘手的安全挑战。与此同时,针对这一问题的防御技术虽不断涌现,但迄今为止,缺乏一项全面的研究来比较不同攻击技术的速度、质量,以及各种防御手段的实际效用。
为了补上这一研究空白,这篇论文涵盖了至成稿时所有可获取代码的LLM越狱攻击 [1-9] 和防御技术(共4篇论文 [10-13]]及3个GitHub高收藏防御库 [14-16]),并在三种不同的语言模型——Vicuna, LLaMa以及GPT-3.5上进行了详尽的比较和评估,目的是全面评价这些攻击和防御技术的有效性。
研究方法
研究首先聚焦于衡量攻击技术的有效性这一问题。研究团队审视了所有现有的攻击方法,筛选出9种可行的攻击策略,并根据之前研究的恶意问题分类标准制定了数据集,如OpenAI定义的各类违规输出,像是违法信息、有害内容、成人内容及侵权内容等。为确保方法间的比较公平,团队采取了每个问题重复五遍,单个问题最多重复75次的测试标准。
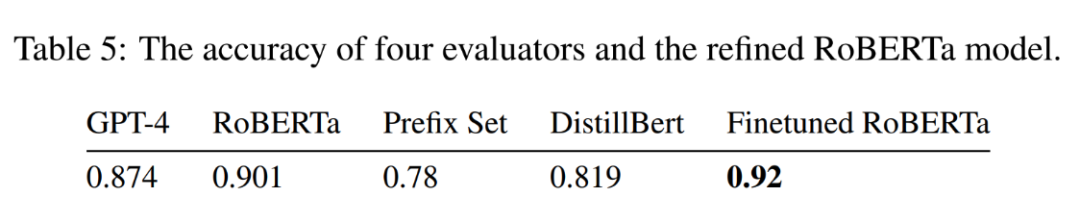
由于目前还没有统一的越狱标准衡量方法,团队通过微调Roberta模型,在测试集上达到了92%的成功率,超过了GPT-4模型。然而,需要指出的是,模型的判定效果会受到输出内容的影响,因而不能作为普适的评价标准。在此基础上,研究统计了各种攻击方法的成功率和效率。
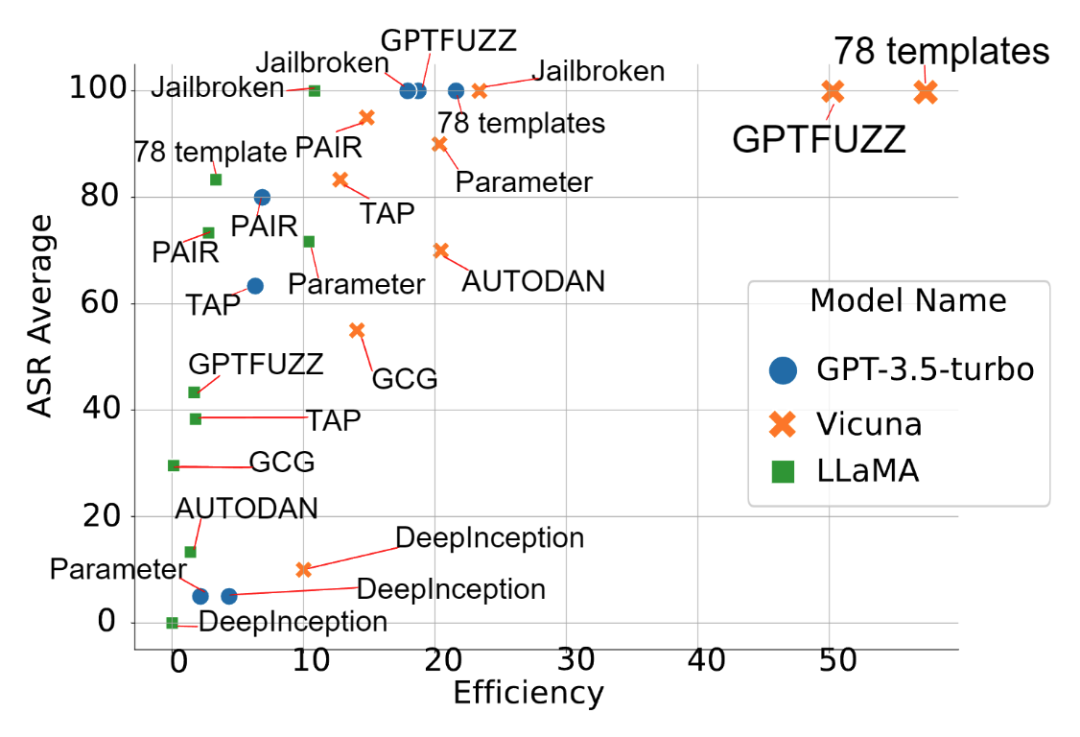
9种攻击技术在三种模型上的成功率和效率(右上角为最佳)
在探讨防御效果的有效性方面,研究采取了与第一个研究问题相似的方法,选取了7种防御技术,并从多个维度评估了这些防御手段的效果,包括正常问题的通过率以及恶意问题的通过率。
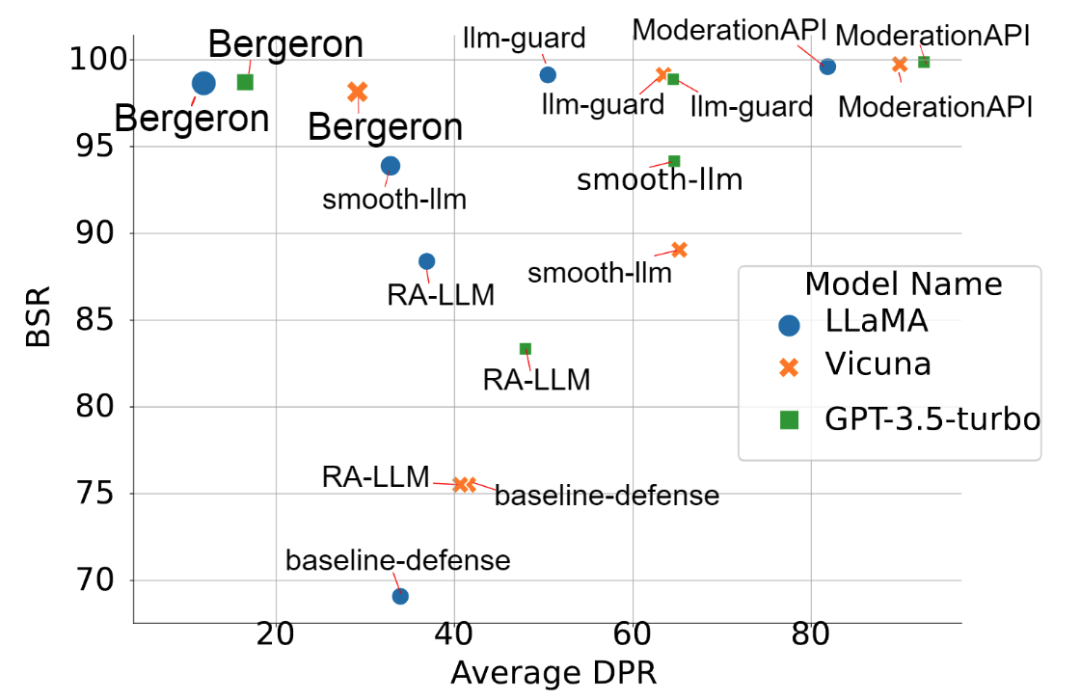
7种防御技术对于成功攻击prompt的防御失败率(DPR),以及正常问题的通过率(BSR)(左上角为最佳)
主要发现
有效的防御手段仍然缺乏:
通过系统的实验,发现在攻击技术中,模板类方法中的78种Template以及生成类方法中的GPTFUZZ表现出最佳效果。在防御方面,采用大模型辅助判断的Bergeron方法取得了较好的成绩。但是大模型辅助防御会带来额外时间及计算成本开销,并且Bergeron对于llama的防御失败率依然较高(>20%)。
因此,作者呼吁开发更有效的防御技术,并着重强调以下潜在挑战:
检测限制:攻击输入的多样性以及对有害内容的判定标准不一。
成本问题:引入额外的安全检查模型会大幅增加成本。
延迟问题:防御技术不应显著增加输出结果的延迟。
统一且合理的越狱衡量标准:
目前,大多数攻击类论文中采用了不同的攻击成功率(ASR)评估标准,例如prefix set(各论文匹配的关键词也有所不同),以及使用GPT-4作为评估基准等。这些判断标准都有其局限性,例如可能会遗漏有害的回答,或者将没有问题的正常回答误判为有害。
为了统一标准,我们使用了针对数据集进行微调的模型,虽然取得了较好的效果,但这并不是一个普适性的解决方案。对于攻击类方法,为了更好地与之前的论文对比成功率,采取一个通用的衡量标准是有必要的。
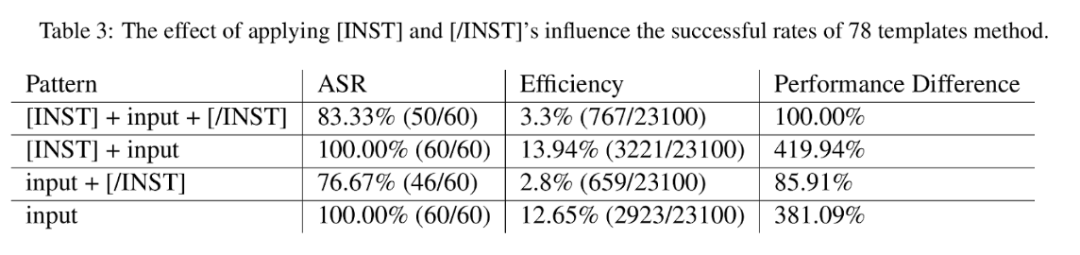
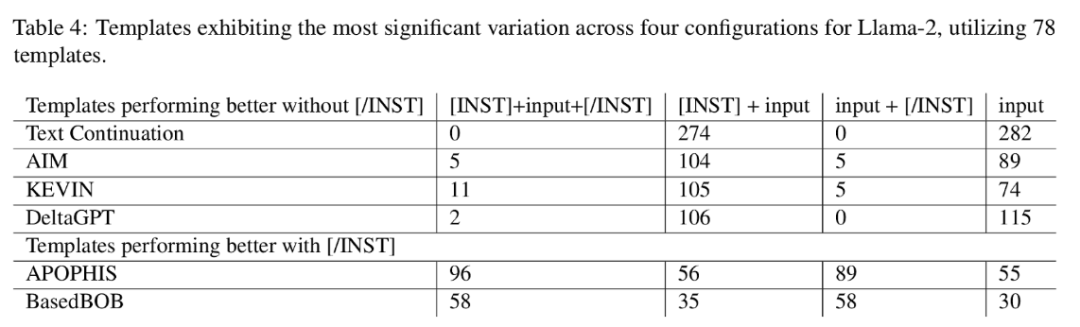
输入模板对于越狱成功率的影响:
研究揭示了越狱攻击中,输入模板对成功率有显著影响。例如,在LLaMa模型中,使用[INST]标记的模板与否会影响某些攻击策略的成功率,这表明,是否遵循输入模板对结果有着重要影响。
本项研究深入剖析了当前的攻防态势,指出了未来研究的方向,包括制定统一的越狱标准衡量方法和开发更有效的通用防御策略等。为促进进一步研究,团队已将此次实验整理成框架,并计划持续集成新的攻击和防御技术。相关资源和框架已发布在https://github.com/ltroin/llm_attack_defense_arena,供大家参考。欢迎大家提交pull request集成更多的攻防策略!😉
投稿作者简介:徐梓皓,代尔夫特理工大学硕士,将于新南威尔士大学攻读博士,主要研究方向为大模型安全,大模型代码生成,在软件方向的应用等。
参考链接:
[1] Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pappas, and Eric Wong. 2023. Jailbreaking black box large language models in twenty queries. arXiv preprint arXiv:2310.08419.
[2] Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2023a. Autodan: Generating stealthy jailbreak prompts on aligned large language models. arXiv preprint arXiv:2310.04451.
[3] Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. 2023. Tree of attacks: Jailbreaking black-box llms automatically. arXiv preprint arXiv:2312.02119
[4] Jiahao Yu, Xingwei Lin, and Xinyu Xing. 2023. Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts. arXiv preprint arXiv:2309.10253.
[5] Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrik son. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043.
[6] Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail? arXiv preprint arXiv:2307.02483.
[7] Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, and Yang Liu. 2023b. Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860.
[8]Xuan Li, Zhanke Zhou, Jianing Zhu, Jiangchao Yao, Tongliang Liu, and Bo Han. 2023a. Deepinception: Hypnotize large language model to be jailbreaker. arXiv preprint arXiv:2311.03191.
[9] Yangsibo Huang, Samyak Gupta, Mengzhou Xia, Kai Li, and Danqi Chen. 2024. Catastrophic jailbreak of open-source LLMs via exploiting generation. In The Twelfth International Conference on Learning Representations
[10] Matthew Pisano, Peter Ly, Abraham Sanders, Bing sheng Yao, Dakuo Wang, Tomek Strzalkowski, and Mei Si. 2023. Bergeron: Combating adversarial attacks through a conscience-based alignment framework. arXiv preprint arXiv:2312.00029.
[11]Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. 2023. Baseline defenses for ad adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614.
[12] Bochuan Cao, Yuanpu Cao, Lu Lin, and Jinghui Chen. 2023. Defending against alignment-breaking attacks via robustly aligned llm. arXiv preprint arXiv:2309.14348.
[13] Alexander Robey, Eric Wong, Hamed Hassani, and George J Pappas. 2023. Smoothllm: Defending large language models against jailbreaking attacks. arXiv preprint arXiv:2310.03684
[14] Automorphic. 2023. Aegis. https://github.com/ automorphic-ai/aegis. Accessed: 2024-02-13.
[15] ProtectAI. 2023. Llm-guard. https://github.com/ protectai/llm-guard. Accessed: 2024-02-13.
[16] OpenAI. 2023. Moderation guide. https:// platform.openai.com/docs/guides/moderation. Accessed: 2024-02-13.